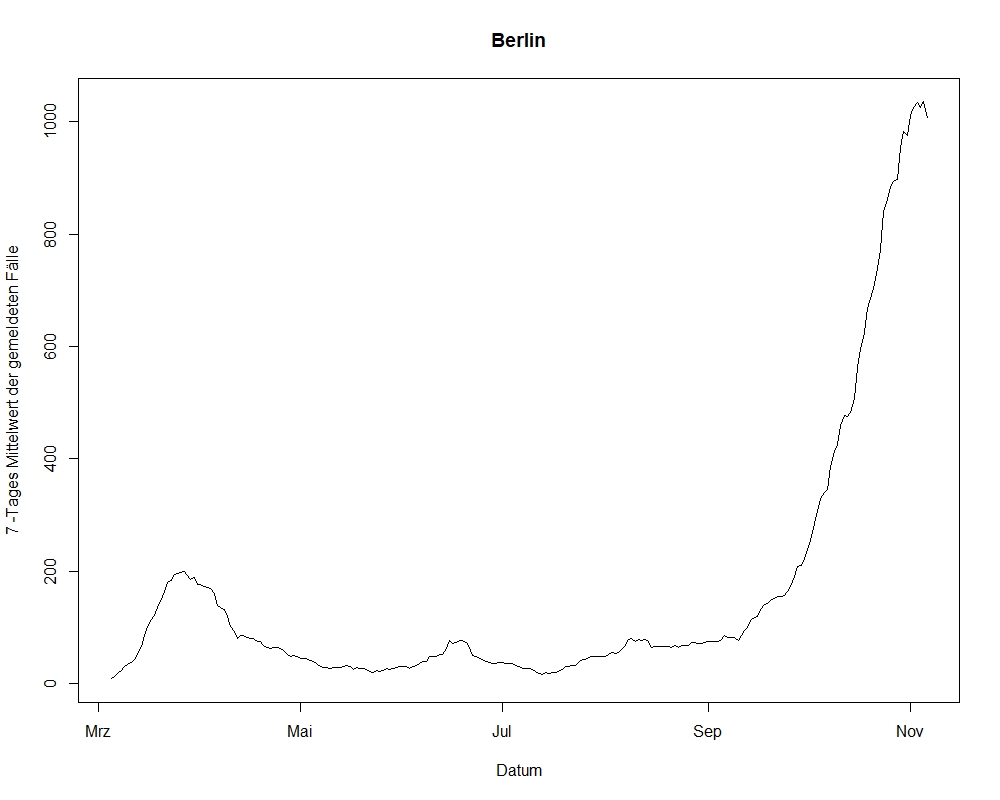
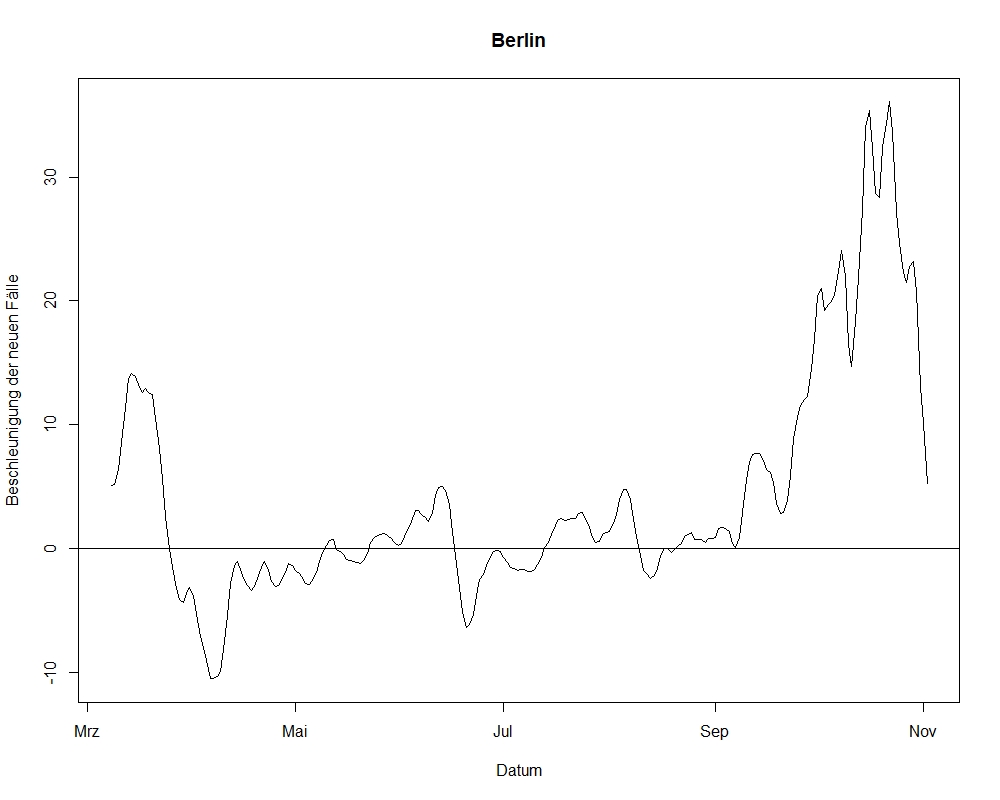
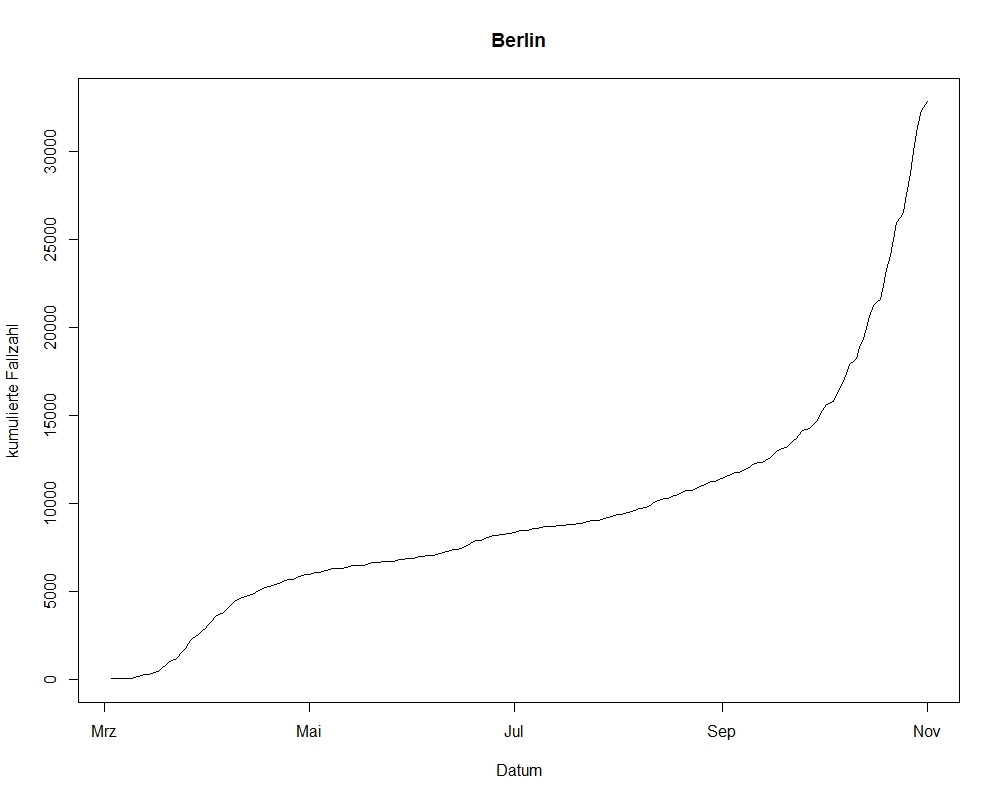
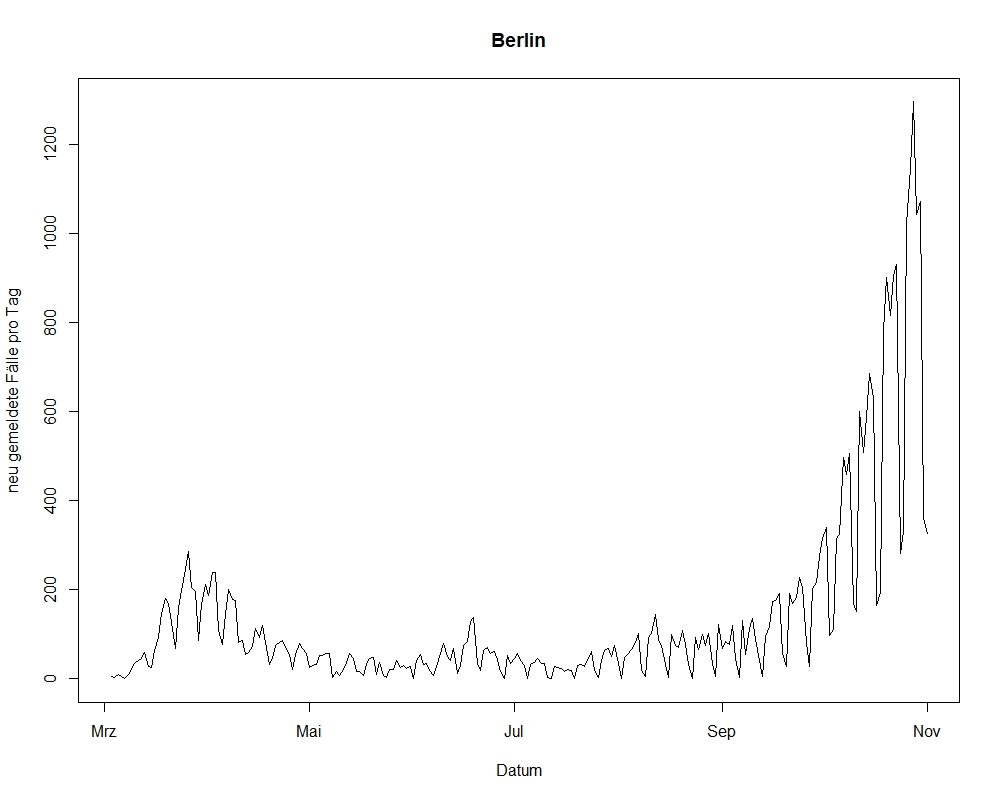
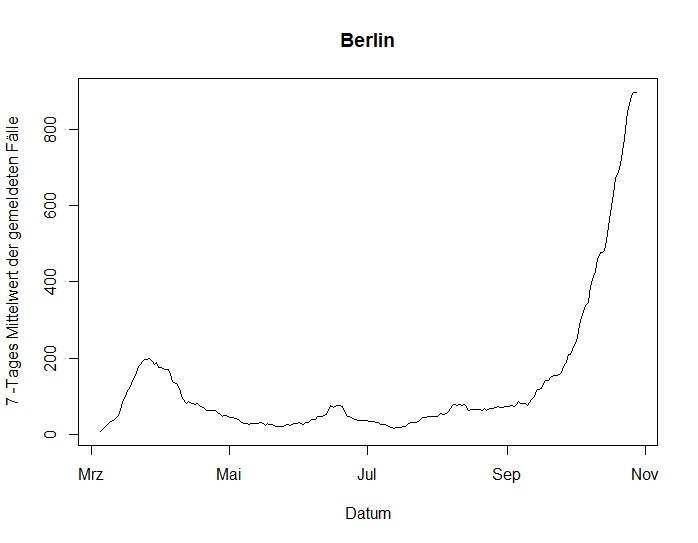
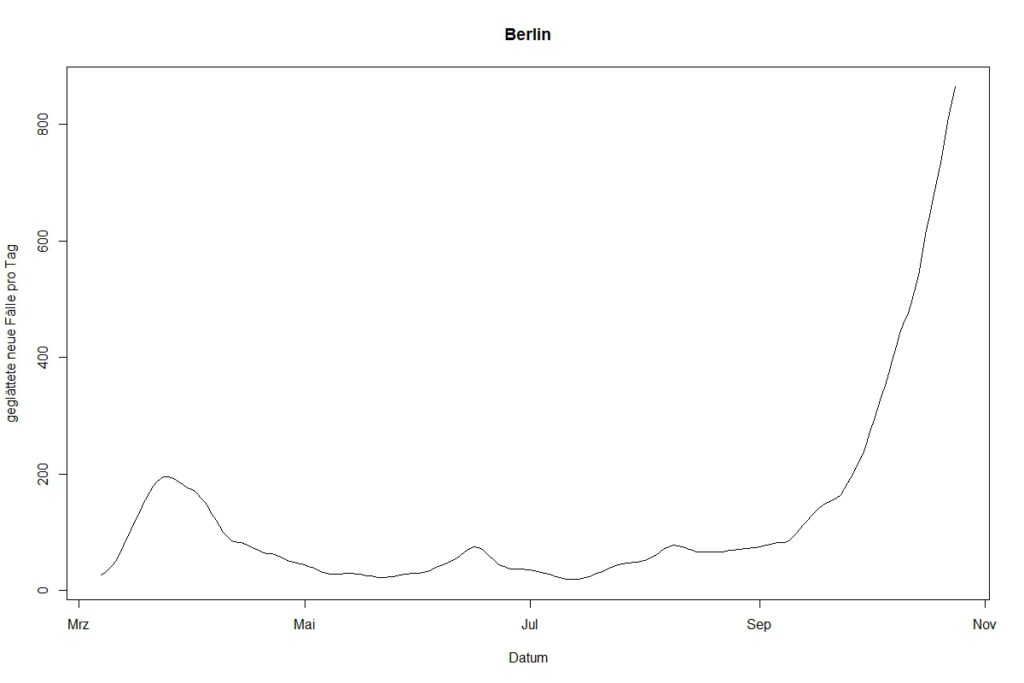
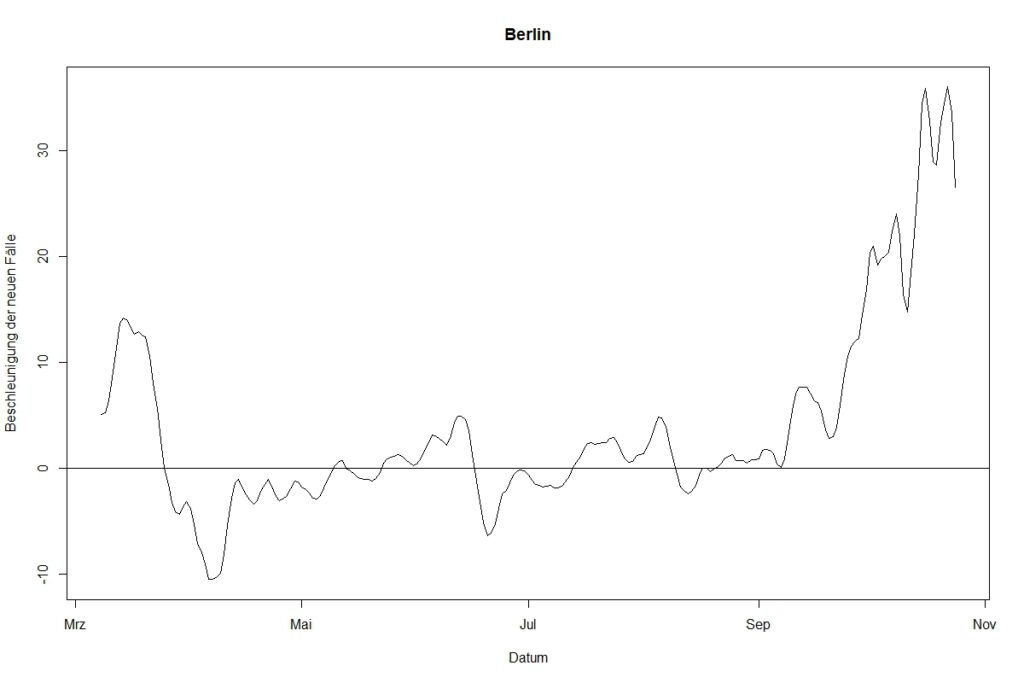
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
| library("audio")
# gen_sin(): generate sine signal
#
# sample rate=44100 Hz
# f: frquency in Hz
# ms: duration in milliseconds
gen_sin<-function(f, ms)
{
x<-NULL
k=44100/(2*pi*f)
x<-sin(0:(44100*(ms/1000))/k)
return(x)
}
# Check
gen_sin(440,10)
# envelope(): generate simple linear AD envelope
#
# x: signal returned by gen_sin
# attack_ms: attack time in milliseconds
# decay: decay time in milliseconds
# max_vol: maximum volume should not exceed 1
# to avoid clipping
envelope<-function(x, attack_ms, decay_ms, max_vol)
{
length=length(x)
attack_start=1
attack_end=44100*(attack_ms/1000)
attack_slope=max_vol/(attack_end-attack_start)
decay_end=length(x)
decay_start=decay_end-44100*(decay_ms/1000)
decay_slope=max_vol/(decay_end-decay_start)
env<-rep(max_vol, length)
volume_attack=0
for(i in attack_start:attack_end)
{
env[i]=volume_attack
volume_attack=volume_attack+attack_slope
}
volume_decay=max_vol
for(i in (decay_start):decay_end)
{
env[i]=volume_decay
volume_decay=volume_decay-decay_slope
}
return(env)
}
# Checks
x<-gen_sin(440,100)
length(x)
plot(x)
env<-envelope(x,50,50,0.5)
length(env)
plot(env)
# gen note(): generate note
#
# f: frequency in Hertz
# ms: duration in milliseconds
# attack_ms: attack time in milliseconds
# decay: decay time in milliseconds
# max_vol: maximum volume should not exceed 1
# to avoid clipping
gen_note<-function(f, ms, attack_ms, decay_ms, max_vol)
{
x<-gen_sin(f,ms)
env<-envelope(x,attack_ms, decay_ms, max_vol)
env_signal<-x*env
return(env_signal)
}
x<-gen_note(440,1000,100,500,1)
play(x)
plot(x)
# gen_triad(): generate frequencies of a triad
# note: base note of triad
# freq_scale: scale frequencies
gen_triad<-function(note, freq_scale)
{
chord<-NULL
for(i in 1:3)
{
index=((note-1)%%16)+1 # R starts counting with 1
note=note+2
chord<-c(chord, gen_note(freq_scale[index], 400,40,200,0.8))
}
return(chord)
}
# Frequencies of the C major scale
freq_scale<-c(261.63, 293.66, # C4 D4
329.63, 349.23, # E4 F4
392.00, 440.00, # G4 A4
493.88, 523.25, # B4 C5
587.33, 659.25, # D5 E5
698.46, 783.99) # F5 G5
# Check
plot(freq_scale)
# Play C Major chord
x<-gen_triad(1, freq_scale)
play(x)
### Generate piece ###
# Source of the alogrithm:
# Spiegel, L. (1982). Sonic Set Theory: A Tonal Music Theory for Computers.
# In Proceedings of the Second Annual Symposium on Small Computers and the Arts.
#
stages<-matrix(c(0, 0, 1, 0, 0, 0, 0,
0.5, 0, 0, 0, 0, 0.5, 0,
0, 0.5, 0, 0.5, 0, 0, 0,
0, 0, 0, 0, 0.5, 0, 0.5,
0.5, 0, 0, 0, 0, 0.5, 0), byrow=TRUE, ncol=7)
# Base notes of chords
base_notes<-rep(1:7)
piece<-NULL
cycles=0
start=1
max_cycles=4
while(cycles<max_cycles)
{
for(i in start:5)
{
index<-sample(base_notes,1, p=stages[i,])
piece<-c(piece, gen_triad(index, freq_scale))
cat(index)
}
start=sample(2:5,1)
cycles=cycles+1
}
play(piece) |